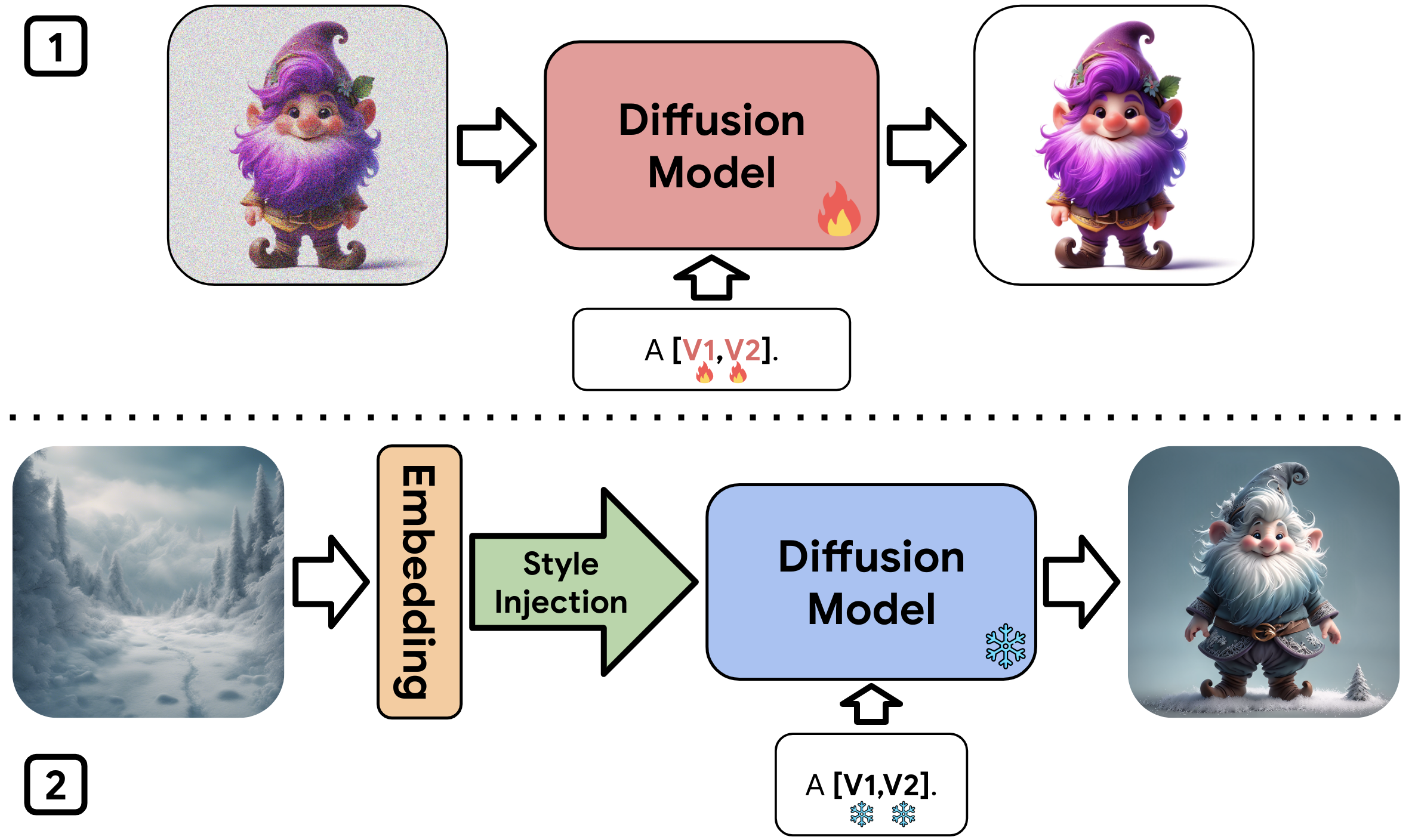
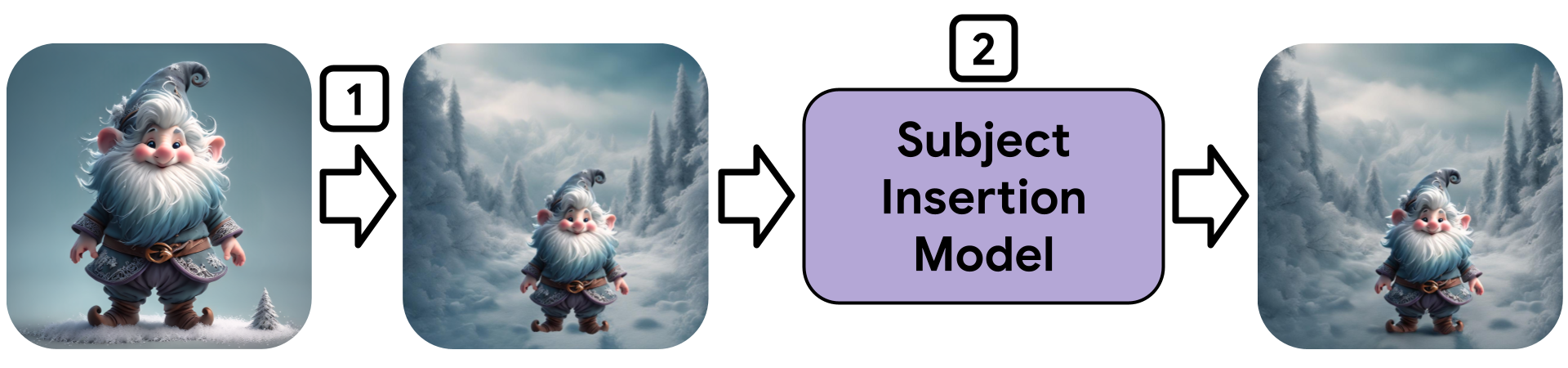
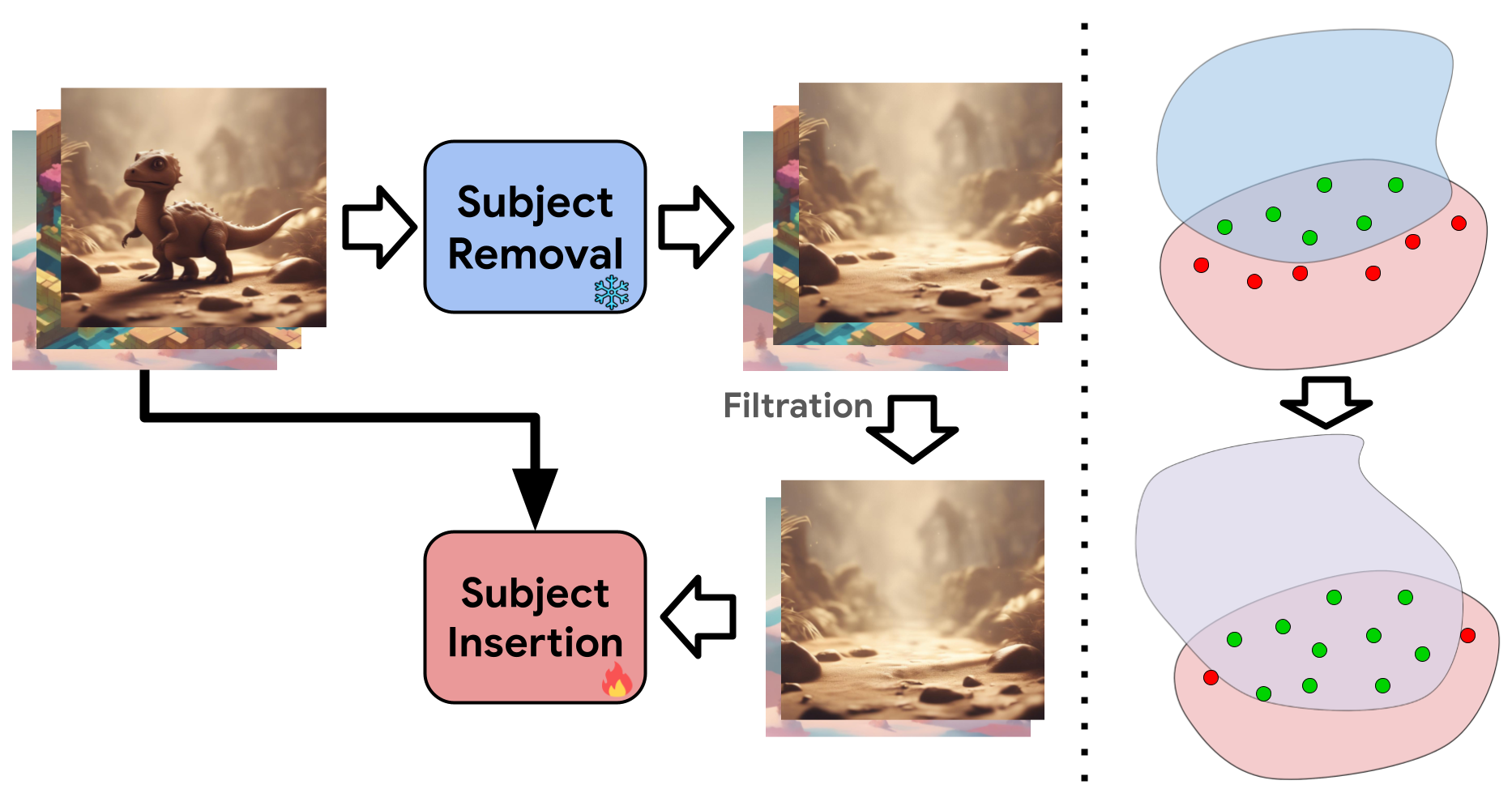
Using Magic Insert we are, for the first time, able to drag-and-drop a subject from an image with an arbitrary style onto another target image with a vastly different style and achieve a style-aware and realistic insertion of the subject into the target image.